Computational Text Analysis for Humanists and Social Scientists
Increasingly, humanity’s cultural material is being captured and stored in the form of electronic text. From historical documents, literature and poems, diaries, political speeches, and government documents, to emails, text messages, and social media, students from the humanities and social sciences now have access to immense amounts of rich, and diverse, text. Scholars are increasingly using computational methods to analyze these new sources of text in order to ask, and answer, a diverse array of questions about the social world: Does social media reflect public political opinion, or drive it? What determines trust in online communities? What types of blog posts get censored in China and why? Are diurnal and seasonal mood cycles cross-cultural? What was the form of cultural and institutional change through the “civilizing process” in England between the 16th and 20th centuries? What is the life cycle of a literary genre? What are textual allusions in Classical Latin poetry? Can the FBI really analyze 650,000 emails in 3 days? (Spoiler: Yes, they can!)
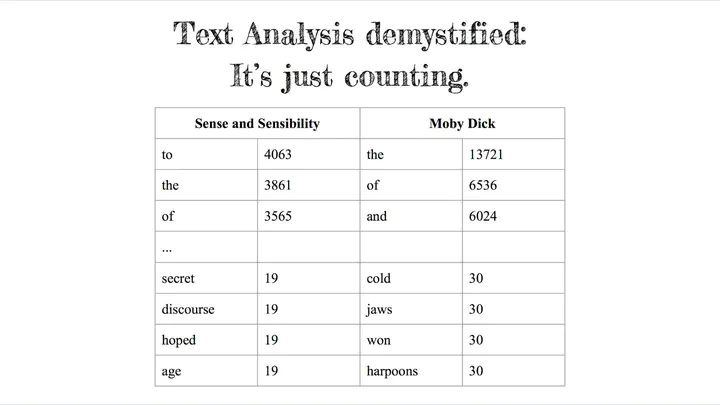
In this workshop students learn cutting-edge methods to analyze large amounts of texts to explore questions fundamental to the humanities and social sciences. We will not have computers read the text for us. Instead, students harness the superior ability for computers to count and extract patterns from text, and use this output to enhance our own critical thinking and interpretive analyses.
Laura K. Nelson
Associate Professor of Sociology
I use computational methods to study social movements, culture, gender, institutions, and the history of feminism. I’m particularly interested in developing transparent and reproducible text analysis methods for sociology using open-source tools.