The Future of Coding: A Comparison of Hand-Coding and Three Types of Computer-Assisted Text Analysis Methods
In *Sociological Methods & Research
Abstract
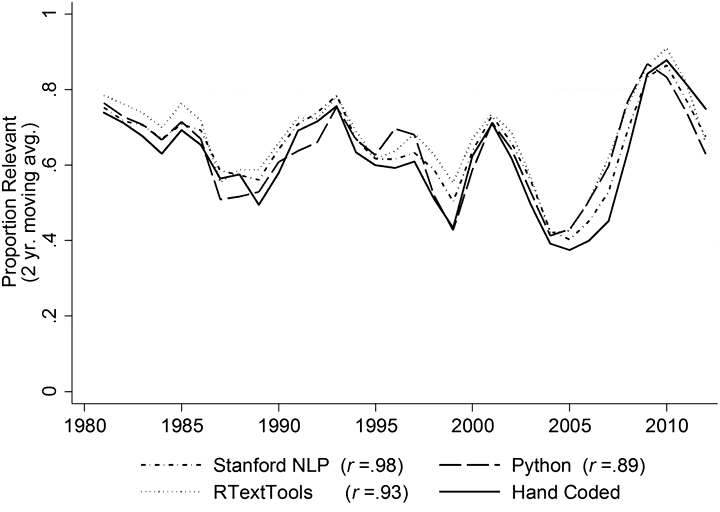
Advances in computer science and computational linguistics have yielded new, and faster, computational approaches to structuring and analyzing textual data. These approaches perform well on tasks like information extraction, but their ability to identify complex, socially constructed, and unsettled theoretical concepts—a central goal of sociological content analysis—has not been tested. To fill this gap, we compare the results produced by three common computer-assisted approaches—dictionary, supervised machine learning (SML), and unsupervised machine learning—to those produced through a rigorous hand-coding analysis of inequality in the news (N = 1,253 articles). Although we find that SML methods perform best in replicating hand-coded results, we document and clarify the strengths and weaknesses of each approach, including how they can complement one another. We argue that content analysts in the social sciences would do well to keep all these approaches in their toolkit, deploying them purposefully according to the task at hand.
Laura K. Nelson
Associate Professor of Sociology
I use computational methods to study social movements, culture, gender, institutions, and the history of feminism. I’m particularly interested in developing transparent and reproducible text analysis methods for sociology using open-source tools.